Datafangstløsningen er nå oppdatert i produksjon. De viktigste nyhetene:
Forfatterarkiv: jankristian
APISKRIV 2017-1 produksjonssatt
NVDB APISKRIV er nå oppdatert i produksjon. De viktigste endringene er angitt under:
URL’er til vegkart og NVDBAPI bør URL-Encodes
Applikasjonstjenerene som vegkart og NVDB-API LES kjører på ble oppgradert like før påske. Den nye versjonen av Tomcat avviser nå blankt URL/URI’er med tegn som ikke er ihht internett-standardene RCF-1738 og RFC-2396, og forespørsler med slike tegn kommer aldri frem til API’et.
Re-indeksering torsdag 9.februar 2017
EDIT fredag 10.2: Vi er tilbake i normal drift, men mangler litt driftskontrakt
Kjente feil 10.2: Fiksa
Mangler driftskontrakt 1103 Stavanger
torsdag 9. februar skjer det to ting som går ut over alle brukere av Vegkart og NVDB api.
- Vi skrur av oppdatering.
- På dagtid 9.2 vil vi ikke overføre endringer fra NVDB-databasen til NVDB api og vegkart.
- Husk at du kan sjekke status på dataoverføring fra NVDB med «info»-knappen i vegkart og denne funksjonen.
- Full re-indeksering.
- Om ettermiddagen / kvelden torsdag 9.2 kjører vi full re-indeksering
- Først blir det et par timer uten data overhodet i NVDB api og Vegkart
- Deretter vil objekttypene gradvis komme på plass igjen (rekkefølge etter objekttypenummer, dvs først 3 Skjerm, 5 rekkverk osv).
- Re-indeksering burde være ferdig ca midnatt natt til fredag 10.2.
- Normal drift fra fredag morgen
- Fredag morgen skrur vi på oppdateringen, slik at du igjen finner de ferskeste data i Vegkart og NVDB api
Bakgrunnen er en (liten, rent teknisk) datakatalogendring. Dette er en nødvendig forberedelse til den datakatalogendringen som kommer i slutten av februar.
Vi beklager de ulempene dette får for våre brukere!
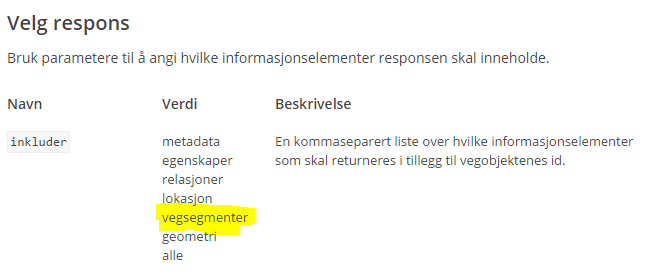
I 2016 hadde vi 423 millioner oppslag mot NVDB api
423 millioner oppslag er jo en del. Klientapplikasjonen «Ukjent» står for mesteparten, med vegkart som god nummer 2.
For din egen del er det lurt om du angir X-Client og X-Kontaktperson i headeren på kallet, slik som beskrevet her:
"X-Client": "NVDB Rapporter"
"X-Kontaktperson": "ola@nordmann.no"
Da får vi muligheten til å kontakte deg om noe er galt, og din applikasjon kommer med i statistikken.
FME eksempel for segmenterte data
Jeg har laget et FME workspace som utnytter muligheten til å få «delt opp» lange objekter i kortere segmenter. Hvert segment har unike vegreferanseverdier og veglenkeposisjoner. (I tillegg unngår man alle «multilinestring» – geometrier).
Trikset er nøkkeordet inkluder=vegsegmenter (evt inkluder=alle). Slik:
https://www.vegvesen.no/nvdb/api/v2/vegobjekter/616/91452898.xml?inkluder=vegsegmenter
Med NVDB api V2 kan man velge å få lange objekter delt opp i segmenter med unike vegreferanseverdier og veglenkeposisjoner. Dokumentasjon
Det vil si at i stedet for:
- en geometri for hele objektet
- en liste med vegreferanser
- en annen liste med veglenker
- og plunder med å koble en veglenke-bit til riktig vegreferanse + riktig bit av geometri
Så får vi
- Ett eller flere segmenter
- Hvert segment har sin egen «bit» av objektet med
- En enkel vegreferanseverd (med unike vegnummer hp, frameter og tilmeter)
- En bit av en enkelt veglenke (ID, fraposisjon, tilposisjon)
- Geometrien som hører til.
https://github.com/LtGlahn/Nvdbapi_v2_FME#nvdbapi_v2_bruksklassefmw
Re-indeksering 2.januar 2017
Oppdatering 2.1.2016 23:12: Jobben er fullført og alt ser greit ut (så langt). Kontraktsområder krever dog en restart av vegkart; dette gjøres 3.1
På grunn av kommunesammenslåing må vi gjøre full re-indeksering av NVDB api’et. Dette gjøres om ettermiddagen 2. januar 2017, mot slutten av arbeidsdagen/etter arbeidstid. Følg med NVDBapi på twitter for oppdateringer.
Når re-indekseringen starter vil Vegkart og NVDB ha mangelfulle data i opptil et par timer. Dernest er en periode der de fleste objektene er på plass, men uten data om vegtilknytning (vegreferanse, veglenke), samt øvrig informasjon som avledes fra vegnettet (koordinater for senterlinje, kommune, fylke m.m.). Søk på riksvegruter, vegnummer etc vil heller ikke gi korrekte resultat.
Cirka ved midnatt natt til 3. januar regner vi med at alt er ferdig og på plass!
Historiske data, trafikkmengde
Flere har etterspurt historikk for trafikkmengde fra NVDB. Nå er det lagt ut her på spatiaLite (sqlite) og esri filgeodatabase (.gdb) – format.
ftp://vegvesen.hostedftp.com/~StatensVegvesen/opnevegdata/historiskedata
Historikk kan fremstilles på flere måter. Det vanligste er nok øyeblikksbilder, det vil si at vi gjengir situasjonen slik det var registrert på en gitt dato. I stedet har jeg valgt å legge ut FULL historikk på ALLE trafikkmengde-objekter i NVDB. Det gir et riktigere bilde av datasettet, og åpner for flere typer analyser. Denne presentasjonen er kanskje til hjelp, den viser i hvert fall noen av problemene grafisk.
Vi regner med å ha en form for historikk tilgjengelig i Vegkart og NVDB api i løpet av
20172018?– med forbehold om at andre oppgaver kan smyge seg foran i køen. Vi er heller ikke sikre på hvilke funksjoner dette vil inneholde – mest trolig en form for øyeblikksbilder, dvs at man kan søke per dato.
Trafikkmengde er ikke koblet mot vegreferanse. Hvis du er avhengig av å vite et spesielt vegnummer så må du koble dette mot vegreferanse-informasjon (som også er publisert, samme sted).
Egenskapsnavn og verdier
Jeg har valgt å bruke de samme egenskapsnavnene som arc map NVDB plugin – med noen tilpasninger. Så hvis du laster ned ferske data med Arc map vil du kjenne igjen – og forhåpentligvis kunne bruke datasettene litt om hverandre.
Rent praktisk betyr det at vi unngår slikt som komma, mellomrom og slasher, men ikke er redd for norske tegn. Underscore ( _ ) brukes i stedet for tegn vi ikke liker. Det betyr at ÅDT, total har blitt til ÅDT__total.
Dette med navngiving er en av grunnene til at det litt krevende å lage «datadumps» fra NVDB – i hvert fall hvis du ønsker å bli brukt i annen programvare. Internt i NVDB brukes kun numeriske ID’er for å holde styr på ting, men ÅDT__total er en smule mer brukervennlig enn 4623. Men ikke alle NVDB-navn er så rett fram!
Det er mye progamvare som furter litt over egenskapsnavn som Merknad Skade på erosjonssikring ved inn- og utløp.
Å oversette 4122 egenskapsnavn (datakatalog v2.07) til noe som er lesbart både for menneske og maskin er … dessverre ikke helt rett fram.
Mer teknisk
Disse dataene er ikke hentet direkte fra NVDB, men fra et søstersystem vi kaller TNE (Transport Network Engine). Her er NVDB-data tilrettelagt for GIS-formål – og dette innebærer en del kompromiss. Blant annet blir NVDB-data kappet i mindre biter hvis f.eks. de er lengre enn én veglenke eller ett vegreferanse-objekt. Bitene blir numerert med variabelen TNE_SEQ_NO. I tillegg har TNE sin egen forståelse av topologinivå: Vegtrasé, kjørebane og kjørefelt oversettes til tallkoder (0-3) i egenskapen TNE_topologylevel. For sporbarhet lar vi denne informasjonen følge med datasettet.
Dette er IKKE en komplett gjengivelse av navigerbart vegnett. Det er et utdrag av fagdata på øverste topologinivå. Man kan få en forståelse av vegnettets utbredelse og endring over tid, og det har sikkert mange anvendelser. Men ruteplanlegging er IKKE blant de tingene dette datasettet bør brukes til.
Reindeksering – hva betyr det?
Når du ikke kan bruke Vegkart og NVDB api så er det som regel re-indeksering på gang.
Bak NVDB api’et (som igjen står bak vegkart) har vi en søkeindeks proppfull med NVDB-data. Denne holdes fersk — alle endringer i NVDB overføres til søkeindeksen fortløpende.
Noen ganger må denne søkeindeksen tømmes helt før alt fylles inn på ny. Som regel fordi vi har laget noe nytt i NVDB api, eller fordi noe har gått galt.
Ekstra dumt er det hvis re-indeksering feiler – da må vi gjøre alt på nytt igjen, med ulempe for brukerne våre. Dette skjedde f.eks desember 2016.
Hva betyr reindeksering for meg?
Når vi starter så tømmes alt av data fra indeksen, og ingenting virker i Vegkart eller NVDB api. Etter ca en time begynner det å bli data tilgjengelig. Vi begynner med de laveste objekttypenumrene (3 – skjerm, 5 – rekkverk), og jobber oss oppover. Etter ca 6-8 timer er vi ferdige.
Som hovedregel starter re-indeksering mot slutten av arbeidsdagen/tidlig ettermiddag. Og normalt går det uker eller måneder mellom hver gang vi må re-indeksere.
Kan dere ikke re-indeksere uten ulemper for brukerne?
Vi jobber med en løsning for re-indeksering uten driftsavbrudd eller andre ulemper. Denne skal på plass i løpet av 2017.
Koordinatkrangel i NVDB api V1
Vi har nettopp satt i produksjon en ny versjon 1 av NVDB api.
- Hvis du bruker lengde- og breddegrad så er rekkefølgen nå er byttet om – eller mer presist: Vi har byttet tilbake slik det var før juni 2016.
- Vi serverer nå kun 2D koordinater. Ikke en blanding av 2D og 3D.
Mange eksisterende klienter fikk problemer på grunn av dette. Derfor ruller vi V1 tilbake slik det var før juni 2016. Beklager at dette tok tid!
Merk at V1 nå avviker fra V2 på de to punktene over.
Koordinatkrangel.
Dette med rekkefølgen på koordinater for lengde- og breddegrad har gitt mye hodebry.
- Matematikere og programmerere har ofte foretrukket rekkefølgen X, Y, det vil si rekkefølgen (øst, nord) – eller (lon, lat) (lengdegrad, breddegrad).
- Geografer har likt best rekkefølgen (grader N, grader E), eller (lat, lon).
Heldigvis har vi internasjonal standardisering. V2 vil følge denne standarden, og det samme gjør skriveAPI’et. Der er det (lat, lon) som gjelder, evt (lat, lon, z) for 3D koordinater.
For V1 gjør vi det motsatt: Her tilbyr vi lengde- og breddegrad som (lon, lat). Altså motsatt av standarden. Og uten høydeinformasjon.
<geometriWgs84>POINT (10.63317257269053 63.42266891319099)</geometriWgs84>
Dette gjelder altså bare lengde- og breddegrad: For UTM-koordinatene er det heldigvis ingen som krangler på rekkefølgen.
Og så er det bare å beklage – både at vi gjorde denne endringen i utgangspunktet, og at det tok såpass lang tid før vi fikk skrudd det tilbake.